:quality(70)/alice.com.br/tech/wp-content/uploads/2024/07/descomplicando-o-apache-kafka.jpg)
Introdução
Na Alice, temos a cultura de tomada de decisões em conjunto para assuntos que impactem a engenharia como um todo. Isso sendo desde a definição da tecnologia a ser usada para desenvolvimento mobile, até a arquitetura de processamento assíncrono dos serviços (spoiler: ela é baseada em Kafka).
Mas antes de contar como e porque escolhemos o Kafka, vale uma n̶ã̶o̶ ̶t̶ã̶o̶ breve introdução sobre ele.
O que é o Apache Kafka?
Resumidamente, o Kafka pode ser definido como um sistema de processamento de stream de dados em tempo real / um sistema de mensageria (messaging system) publish-subscribe distribuído.
Ele possui como principais características — se comparado com outros sistemas de mensageria — um alto throughput, clusterização no DNA (permitindo escalabilidade horizontal), ordenamento e persistência de mensagens com estrutura de disco O(1) (entraremos em mais detalhes sobre o que isto representa).
O que é um sistema de mensageria?
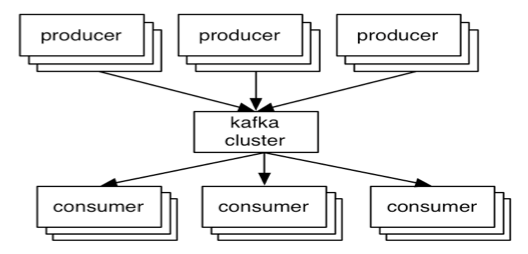
Um sistema de mensageria nada mais é do que uma forma de comunicação assíncrona entre duas (ou mais) aplicações. Neste conceito, as aplicações se comunicam através de uma fila (message queue), de forma totalmente desacoplada, onde o produtor da mensagem (producer) não tem conhecimento de quem a processará, assim como o consumidor (consumer) também não possui ciência de quem a produziu. Ambas as pontas apenas se preocupam com o conteúdo da mensagem.
Existem dois tipos de padrões de mensageria: ponta à ponta (point to point) e publish-subscribe (pub-sub).
Sistema de mensageria ponta à ponta
Um sistema de mensageria ponta à ponta é caracterizado pelo fato de que cada mensagem apenas poder ser consumida uma única vez. Neste sistema, a mensagem é persistida na fila e, a partir do momento que um consumidor lê esta mensagem, ela é automaticamente removida da fila. Exemplos de sistemas neste modelo temos o Amazon Simple Queue Service (SQS) e o Microsoft Message Queuing (MSMQ).
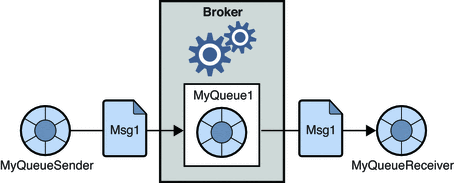
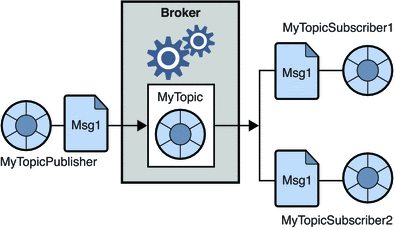
Sistema de mensageria publish-subscribe
No sistema de mensageria publish-subscribe assim como no de ponta à ponta, as mensagens são persistidas em uma fila através de um produtor (publisher). Porém, diferentemente do modelo anterior, os consumidores podem se inscrever/assinar (subscribe) à uma ou mais filas e consumir todas as mensagens destas filas. Neste modelo, todos os consumidores (subscribers) processam todas as mensagens de todas as filas no qual eles se inscreveram. Exemplos de sistemas neste modelo temos o RabbitMQ e o Apache Kafka.
Background
História
Tudo começou em meados de 2010, com uma necessidade do LinkedIn: integração massiva de dados. Um volume enorme de dados era gerado a todo tempo, porém, com as ferramentas existentes na época, não era possível integrar e centralizar estes dados da forma que gostariam e com a escala que precisavam.
Foi então que Jay Kreps e sua equipe surgiram com o conceito do Kafka.
Timeline
Em 2011 tornou-se um projeto open-source, sendo absolvido pela Apache Foundation em 2012.
Em 2014, os engenheiros do LinkedIn responsáveis pelo desenvolvimento do Kafka fundaram a Confluent, empresa com foco em Kafka.
Fun fact
Kafka é desenvolvido em Scala e Java, e seu nome é uma referência ao escritor alemão Franz Kafka. Jay diz que a escolha do nome se deu ao fato de que, devido o Kafka ser um sistema otimizado para escrita, faria sentido ter o nome de um escritor. Além de achar que soava bem para um projeto open source.
Mas por que utilizar Kafka?
Dentre as principais vantagens do Kafka, podemos destacar:
- Sistema de registros: após persistido, um registro (mensagem) nunca mais é mais removido do log (por padrão). Desta forma, é possível “voltar no tempo” e reprocessar todas as mensagens a partir de uma data específica.
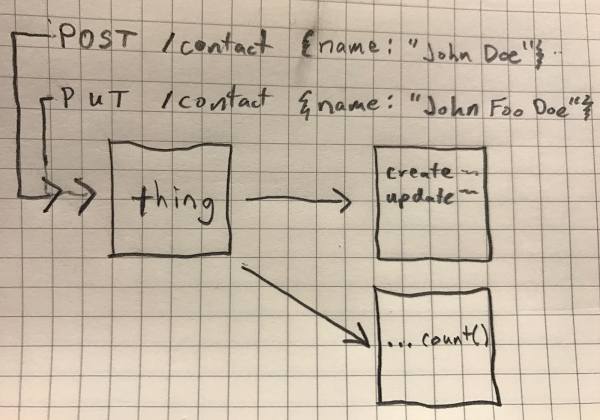
- Ordenamento garantido: ao ser publicada a mensagem A (POST) e então a B (PUT), sempre serão retornadas e lidas nesta mesma ordem (FIFO).
- Centralização: uma mesma mensagem pode servir de input para uma operação SQL e para um registro em um Data Lake.
- Escalabilidade: Kafka é totalmente pensado em clusterização e escalabilidade horizontal.
- Pull over Push: diferentemente de outros sistemas de mensageria (e.g. RabbitMQ) e/ou sistemas de service bus, o Kafka trabalha com um modelo de pulling ao invés de pushing, no qual o consumidor tem de solicitar ativamente a leitura de novas mensagens. Isto possibilita a existência de consumers com velocidades de processamento distintas entre si.
- Performance: possui um alto throughput, comportando centenas de milhares de mensagens/seg até em hardwares mais modestos. Como citado anteriormente, possui persistência de mensagens com estrutura de disco O(1), ou seja, não importa a quantidade de mensagens existentes, a velocidade de escrita sempre se mantém a mesma.
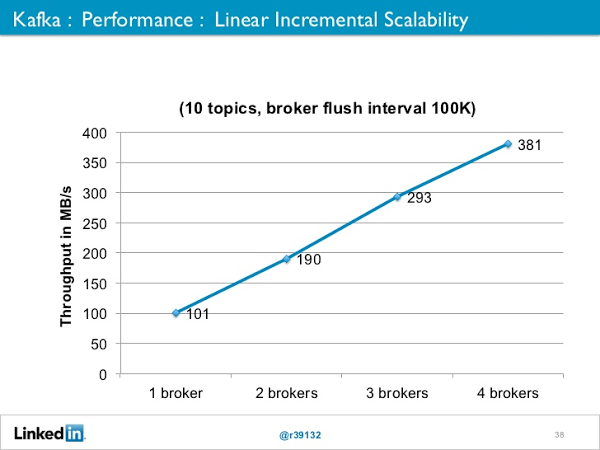
Performance linear
Devido a arquitetura de distribuição que o Kafka implementa, é possível obtermos escalabilidade linear em nosso sistema. Desta forma, para cada nó (broker) adicionado ao cluster, teremos um aumento linear de throughput suportado pelo Kafka.
Use cases
Mesmo o Kafka sendo extremamente versátil, existem alguns casos de uso no qual acaba se destacando. Tais como:
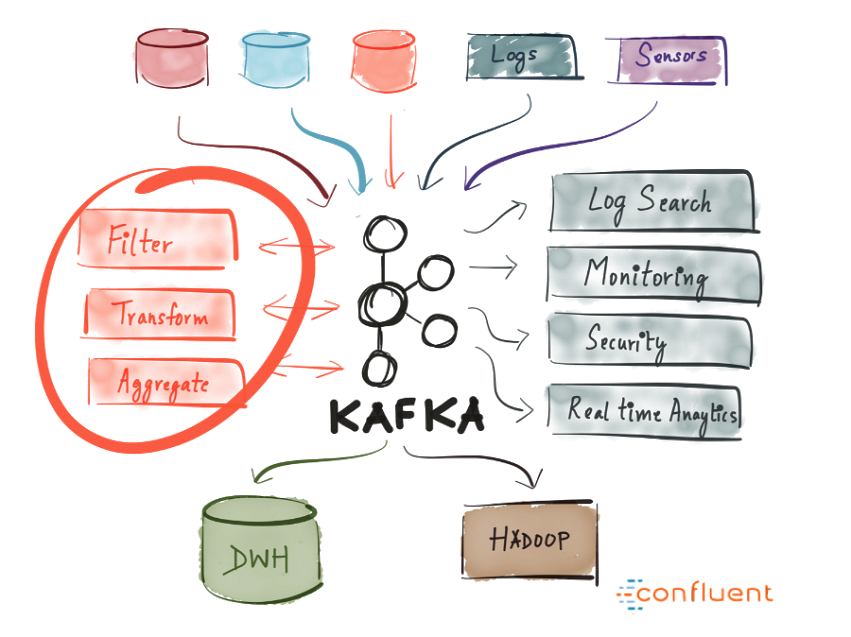
- Hub de eventos: Kafka pode servir de um hub centralizador dos eventos da sua aplicação, permitindo que inputs de diversas fontes de dados sejam concentrados em um único ponto, para então serem potencialmente filtrados, transformados e processados de formas distintas.
- Data pipeline: um dado pode ser persistido no Kafka para então ser replicado para outros repositórios, tais como banco de dados.
- Entry point de Big Data: em casos de utilização de data lakes baseados em storages na nuvem (e.g. AWS S3), Kafka costuma servir como um “buffer” dos dados devido ao seu throughput, armazenando-os até serem transferidos para o storage final.
Semânticas
Registros
Os registros (records) são as mensagens persistidas em uma fila (tópico). Um registro é composto de três componentes: chave, valor e timestamp.
A chave (key) é o que define em qual partição este registro será armazenado (mais detalhes sobre particionamento abaixo). A chave não é obrigatória e, caso não seja fornecida, o Kafka se encarregará de definir a partição correta para este registro.
O valor (value) é o conteúdo do registro, o equivalente ao corpo de uma mensagem. O valor pode conter qualquer dado, desde uma simples string até um objeto serializado em JSON.
O timestamp é a data e hora no qual o registro foi persistido, sendo atribuído automaticamente pelo Kafka no momento da criação do registro.
O registro é sempre imutável e append-only, ou seja, somente é possível incluir novos registros. Uma vez incluído não pode mais ser modificado ou removido.
Os registros são sempre persistidos em disco, não havendo nenhum cache em memória, tanto para escrita quanto para leitura.
Producer e Consumer
O producer é quem será responsável por gerar registros em um tópico e o consumer por ler estes registros. Em ambos os casos, a comunicação é sempre feita com o broker (nó) líder do cluster.
Ao ler um registro, o consumer pode tanto solicitar o último não lido, quanto a partir de uma posição específica.
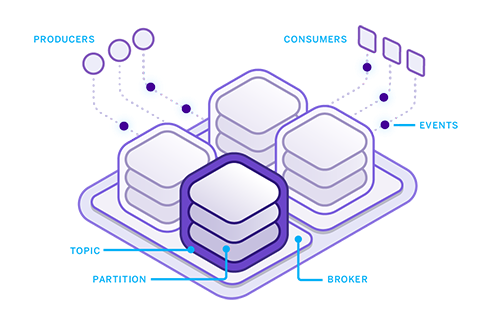
Tópicos
O tópico é a nomenclatura lógica para uma ou mais partições. Basicamente é onde os registros ficam armazenados, sendo equivalente à uma fila, porém considerando todas as partições do cluster.
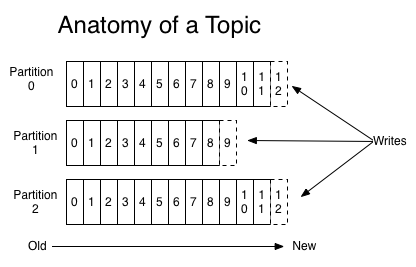
Partições
As partições são as divisões “físicas” de um tópico. Cada partição representará o conjunto de registros de um tópico, em um broker (nó) no cluster.
As partições seguem o modelo de líder/seguidor (leader/follower), onde sempre há ao menos um broker com uma partição principal que recebe todas as operações de leitura e escrita, sendo replicado posteriormente para os demais brokers seguidores em forma de réplica.
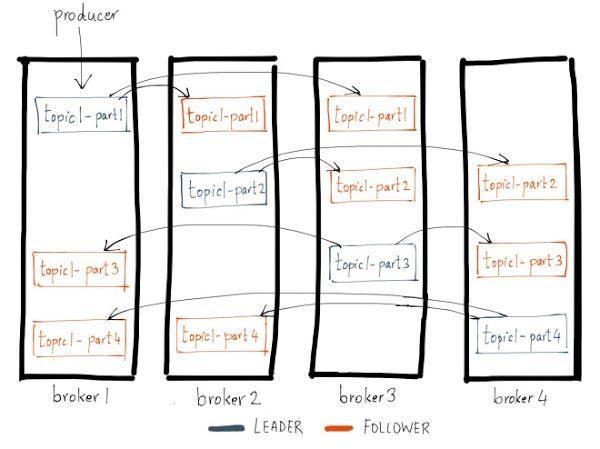
No exemplo acima, temos quatro partições com duas réplicas cada. Cada partição ficará responsável por um conjunto de dados daquele tópico, onde estes mesmos dados serão replicados em cada um dos outros dois brokers seguidores.
O particionamento pode ser feito manualmente ou baseado em uma chave. No primeiro cenário, quem estiver produzindo e/ou consumindo as mensagens, fica responsável por indicar com qual partição deseja interfacear. Já no segundo caso, deve-se definir previamente qual o range de valores de uma chave que cada partição será responsável. Desta forma, ao publicar ou ler um registro, o Kafka ficará encarregado por atribuir a partição correspondente, baseado nas configurações previamente estabelecidas.
Grupos de consumo
Grupo de consumo (consumer group) é o nome lógico para um ou mais consumers. É através dele que se dá a escalabilidade do lado dos consumidores.
Cada grupo lê todas as mensagens de um tópico, dividindo as partições deste tópico por entre os integrantes do grupo.
Cada grupo vai representar um processamento específico (e distinto) dos registros de um tópico em relação ao outro grupo. Já cada integrante de um mesmo grupo representará uma instância de processamento (um processo, uma thread, um container, etc.) idêntica em relação aos consumers deste mesmo grupo.
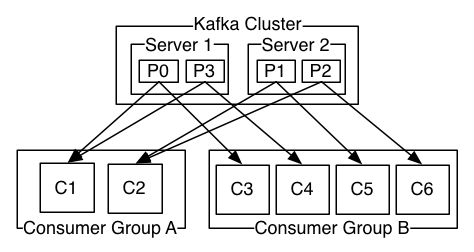
No exemplo acima, temos um tópico dividido em quatro partições, e dois grupos de consumo: grupo A com dois integrantes e B com quatro.
Desta forma, tanto o grupo A quanto o grupo B processarão todas as mensagens de um determinado tópico. Devido ao grupo A possuir dois integrantes, cada integrante ficará responsável pelos registros de duas partições cada. Já no grupo B por possuir quatro integrantes, cada integrante ficará responsável pelas mensagens provenientes de uma única partição cada.
Com isto, é possível ter N processos distintos para um mesmo dado e paralelizar cada um destes processamentos em N instâncias conforme a necessidade, sem gerar concorrência entre si.
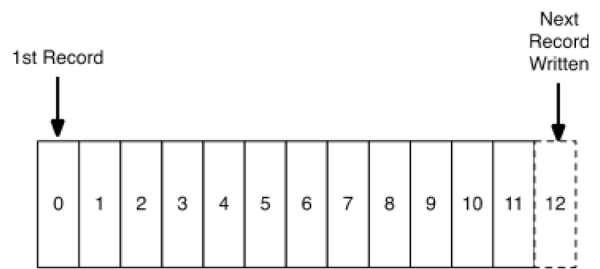
Offsets
Ao inserir um registro em um tópico, o Kafka automaticamente atribui um identificador único sequencial para ele, que consiste basicamente de um índice deste registro na partição daquele tópico.
O offset por sua vez, representa a posição de leitura de um grupo de consumo, em relação à uma partição de um tópico.
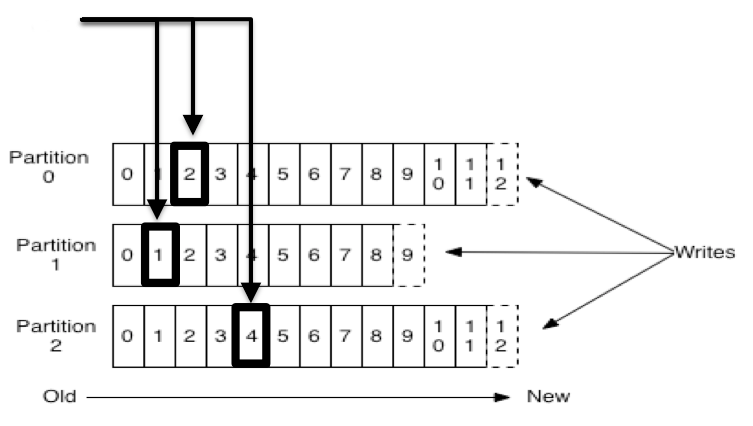
No exemplo acima, temos um tópico com três partições. As setas representando um grupo de consumo e os números destacados os offsets daquele grupo nas respectivos partições.
O objetivo do offset é definir qual foi o último registro lido por aquele grupo de consumo naquela partição, para que assim possa prosseguir com a leitura de onde parou.
O Kafka mantém o tracking dos offsets para que apenas retorne os registros ainda não lidos. Porém, como citado anteriormente, um consumer pode solicitar um registro em uma posição específica.
Conclusão
Conforme pudemos ver, o Kafka é uma excelente ferramenta para criação de sistemas distribuídos, mas assim como qualquer tecnologia, nasceu para resolver problemas específicos e não para ser uma “bala de prata” da persistência de dados.
Que tal fazer parte desse time?
Estamos buscando pessoas que topem o desafio de transformar a saúde no Brasil através da tecnologia. Clica aqui para saber mais das vagas que temos em aberto!
:quality(70)/alice.com.br/tech/wp-content/uploads/2024/10/customer-experience.jpg)
:quality(70)/alice.com.br/tech/wp-content/uploads/2024/07/construindo-uma-healthtech-que-coloca-a-privacidade-de-seus-usuarios-em-primeiro-lugar-1.jpg)
:quality(70)/alice.com.br/tech/wp-content/uploads/2024/07/json-como-integrar-back-end-e-front-end-com-padroes-diferentes.jpg)
:quality(70)/alice.com.br/tech/wp-content/themes/arada/assets/images/single/ideal.jpg)